Urlaub statt Ferien: Ein Fazit nach vier Jahren
Die Universitätsschule Dresden hat mit ihrem “Urlaub statt Ferien” Konzept einen weiteren innovativen Baustein im Petto. Statt starren Ferienzeiten haben die Lernenden mit ihren Familien hier die Möglichkeit, ihre Urlaubstage flexibel zu planen. Im ursprünglichen Konzept wird dabei von 30 frei verteilbaren Tagen gesprochen. Zusätzlich gibt es etwa 15 feste Schließtage, an denen der Schulbetrieb ruht.
Auf den ersten Blick erscheint das Konzept “Urlaub statt Ferien” äußerst attraktiv. Endlich ist es möglich, außerhalb der Hauptsaison zu verreisen, Geld zu sparen und dem Reisestress zu entkommen. Auch fällt endlich die lästige Ferienbetreuung weg die es zu organisieren gilt. Zudem könnten die Lernenden von individuellen Erholungsphasen profitieren, um sich vom anspruchsvollen Lehrplan zu erholen.
Praktisch fällt aber direkt eine Diskrepanz zwischen durschnittlich 75 Tagen Ferien und 55 Tagen Schulfrei auf! Ganze vier Wochen weniger Erholung im Jahr steht den Lernenden an der Unischule zur Verfügung. In der Theorie wird dies damit begründet, dass der Lernalltag für die Lernenden entspannter und entzerrter sei und somit kürzere Erholungsphasen ausreichen.
Doch diese Verringerung und Flexibilisierung der freien Tage hat in der Praxis einige Auswirkungen auf das Schuljahr und die Schulorganisation. Urlaub lieber in der Nebensaison, heißt auf der anderen Seite, dass der Unterricht vermehrt in die heißen Sommermonate fällt. Urlaub außerhalb der Ferien bedeutet auch weniger Ferienangebote, denn sind wir mal ehrlich wer kann denn 30 Tage im Jahr verreisen. Weiter fehlen Schüler azyklisch im Unterricht und Gruppenarbeiten oder die Arbeit in fest getakteten Projekten wird schwieriger koordinierbar, was zu Unruhe und Zeitdruck führt.
Besonders im ersten Jahr sorgten die bürokratischen Abläufe bei der Beantragung für viel Unmut und Unsicherheit bei den Familien. Die zur Verfügung stehenden 30 Tage erwiesen sich als knapp bemessen, um die Erschöpfung, die durch den langen Schultag entsteht, angemessen auszugleichen. Dies gilt nicht nur für die Lernenden, sondern auch für die Pädagogen. Letzteren entfällt eine flexible Verteilung von Vorbereitungsarbeit in der Ferienzeit, da auch sie nur 30 Tage im Jahr nicht am Kind arbeiten müssen.
Auch fiel uns auf, dass sich die Verringerung der freien Tage auf die Möglichkeit auswirkt, gemeinsam mit Kindern aus Regelschulen Ferienzeit zu verbringen. Insbesondere Familien die auch Kinder in Regelschulen haben profitierten nicht von der Lösung, wenn um den Urlaub in der Nebensaison geht. Gleiches gilt für Familien in denen ein Elternteil selbst an einer Schule tätig ist. Somit stehen einige Familien vor dem Dilemma, den Urlaub doch wieder in den Ferien nehmen zu müssen.
In der Ausbaustufe die wir im vierten Jahr erlebten, gab es gar nur 10 Tage flexiblen Urlaub während der Rest durch die Schule in den Ferienzeiten festgelegt wurde. Ich bin ehrlich, den Vorteil dieser Lösung kann ich als Elternteil nicht mehr erkennen.
Insgesamt zeigt sich, dass das Konzept “Urlaub statt Ferien” an der Universitätsschule Dresden in der Praxis nicht unsere Erwartungen erfüllt. Die anfängliche Euphorie wird durch bürokratische Hürden, die Begrenzung der Urlaubstage und die Verringerung der freien Tage getrübt. Es ist wichtig, dass Schulen solche innovativen Ansätze ausprobieren, kritisch reflektieren und gegebenenfalls Anpassungen vornehmen, um den Bedürfnissen der Lernenden sowie deren Familien gerecht zu werden. Im Kontext dieser Reflektionsarbeit schmerzt es mich besonders, dass kaum ein medialer Bericht über die Schule umhin kommt diesen Konzeptanteil positiv heraus zu heben.
Es ist wichtig, dass Bildungseinrichtungen und Familien gemeinsam nach Lösungen suchen, die den Bildungsprozess und die Work-Life-Learn-Balance verbessern. Schließlich sollte Bildung immer das Wohl der Lernenden im Blick haben und gerade hier denke ich hat die Unischule noch viel größere Potentiale als die Zuteilung von freier Zeit im Jahr.
Abschließend möchte ich betonen, dass dies meine persönliche Meinung ist und andere Eltern und Lernende möglicherweise unterschiedliche Ansichten haben.
Lernen im gebundenen Ganztag: Ein Fazit nach vier Jahren
Ein weiterer Baustein des Lernens an der Universitätsschule, war der gebundene Ganztag. Wie hat sich das ganze über vier Jahre entwickelt und wie sind meine Kinder damit klargekommen?
Das Grundkonzept des gebundenen Ganztages an der Universitätsschule Dresden sieht vor, dass Lernenden nicht nur am Vormittag, sondern bis in die frühen Nachmittagsstunden in der Schule lernen und aktiv sein können. Zwischen ca. 8 und 16 Uhr sind sie in der Schule anwesend und können feste Blocks und Kurse besuchen. Dies geht deutlich weiter als simple Ganztagsangebote an regulären Schulen und gilt für alle Altersgruppen.
Das Konzept verspricht dabei einige Vorteile: Eine flexible Ankunftszeit und die Möglichkeit, den Unterrichtsalltag nach eigenen Bedürfnissen zu gestalten, sollen den Lernenden und ihren individuellen Bedürfnissen zugutekommen. Sportliche und kreative Angebote sollen den Tag auflockern und das Lernen abwechslungsreich gestalten. Die Idee hinter dem Konzept ist zweifellos vielversprechend.
Nachdem ich das Konzept des gebundenen Ganztages an der Universitätsschule Dresden näher verfolgt habe, sind mir einige Aspekte aufgefallen, die eine kritische Betrachtung verdienen. Ein Blick auf den Alltag der Lernenden im vierten Jahr der Universitätsschule zeigt, dass der Tag eher 7:30, spätestens um 8:00 beginnt damit auch jeder am verpflichtenden Frühstück teilnimmt. Für Lernende die nicht im direkten Umfeld wohnen bedeutet dies bereits in den frühen Morgenstunden aufstehen zu müssen, um rechtzeitig in der Schule zu sein. Die langen Tage und der frühe Start führten dazu, dass unsere Kinder immer wieder über Konzentrationsprobleme, Müdigkeit und Erschöpfung klagten.
In der Praxis wurde der Lerntag auch nicht bis 16 Uhr ausgedeht. In der Grund und Mittelstufe war spätestens 15:00 Schluss. Aus Sicht der Mittelstufe Montags schon um 14:00 und Freitags 13:00.
Die Pausenregelungen, die anfangs als flexibel und an den individuellen Bedarf angepasst gedacht waren, erwiesen sich als zu starr. Anstelle von regelmäßigen kleinen Pausen zwischen den Unterrichtsblöcken gab es festgelegte Bewegungspausen und eine Mittagspause. Diese begrenzte Anzahl von Pausen wirkte sich negativ auf die Konzentration und die allgemeine Energie der Lernenden aus. Die Tatsache, dass unsere Kinder oft das Bedürfnis nach kurzen Pausen verspürten, jedoch nicht die Möglichkeit hatten, diese einzulegen, verstärkte das Gefühl der Erschöpfung. Diese Müdigkeit schlug sich zweifelsohne auch auf die Motivation zu lernen nieder.
Negativ zu diesen restriktiven Möglichkeiten zur Pausengestaltung kam das die Lernblöcke mit 90 bis 120 Minuten am Vormittag auch deutlich länger sind als das was in normalen Schulen üblich ist und was ein normaler, erwachsener Mensch in einem Arbeitsumfeld leisten kann.
Auch die ursprünglich angekündigten Ganztagsangebote, die als eine Art Auflockerung gedacht waren, erwiesen sich als enttäuschend. Die Bandbreite und Anzahl der Angebote war begrenzt, und die Lernenden konnten nur selten daran teilnehmen. Stattdessen wurde die Zeit nach unserer Beobachtung primär mit regulärem Lernen und Arbeit an Lernbausteinen verbracht, was die Belastung bei unseren Kindern erhöhte.
Zusammenfassend muss ich sagen, dass die Erfahrungen und Beobachtungen die wir als Eltern mit unseren Kindern machen konnten, ein kritisches Licht auf das Konzept des gebundenen Ganztages in dieser spezifischen Umsetzung werfen. Die Idee einer flexiblen Lernumgebung mit ganztägigen Angeboten klang vielversprechend, aber die Realität zeigte, dass der lange Unterrichtstag in Kombination mit einem starren Zeitplan und begrenzten Pausen nicht den erwarteten Nutzen brachte. Dabei kann ich nur vermuten das die mangelnde Flexibilität auch ein Problem fehlenden Personals war und ist.
Mein persönliches Fazit ist, dass eine Überarbeitung des Konzepts notwendig ist, um den Bedürfnissen der Lernenden besser gerecht zu werden. Ein ausgewogenerer Stundenplan, der längere Pausenzeiten und eine flexiblere Aufteilung des Unterrichts ermöglicht, könnte dazu beitragen, die Konzentration und die Lernleistung der Lernenden zu verbessern. Es ist wichtig, die Erfahrungen der Beteiligten ernst zu nehmen und das Konzept so anzupassen, dass es den Zielen einer förderlichen und gesunden Lernumgebung gerecht wird.
Abschließend möchte ich betonen, dass dies meine persönliche Meinung ist und andere Eltern und Lernende möglicherweise unterschiedliche Ansichten haben.
Urlaub in der Wildschönau
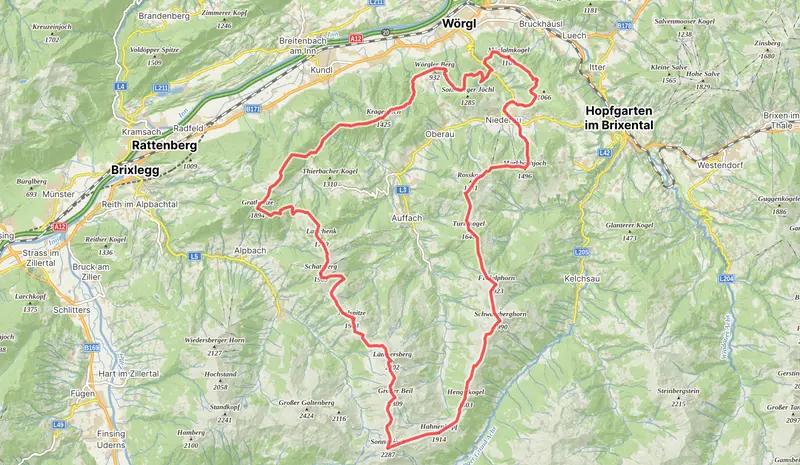
Dieses Jahr führten uns die Sommerferien für eine Woche in die Tiroler Alpen genauer in die Wildschönau. Ferienwohnung, zu fünft, ohne Auto.
Unsere Reise in die malerische Wildschönau in Tirol begann mit einer Zugfahrt. Die Bahnfahrt verlief problemlos, und dank des gut organisierten Nahverkehrs war die letzte Meile zum Zielort ein Kinderspiel. Ein Bus verkehrt stündlich zwischen Wörgl und Auffach, was uns die flexibelste Anreisemöglichkeit ins Tal bot. Aus München verkehrt dabei ein EC aller 2 Stunden. Falls es bei den vorherigen Zügen Verzögerungen gäbe eine vertretbare Wartezeit. Besonders in der Hochsaison empfiehlt es sich, Plätze zu reservieren, um sicherzustellen, dass Familien zusammen sitzen können.
Die Wildschönau hat sich als ein perfektes Ziel für unsere Familie mit Kindern erwiesen. Dank der inkludierten Wildschönau Card, die Teil der Kurtaxe ist, konnten wir kostenfrei den Bus zwischen Niederau und Auffach nutzen sowie die Seilbahnen in beiden Orten. Diese Karte war eine echte Erleichterung, da sie uns anstrengende Aufstiege von 600 bis 800 Höhenmetern ersparte. Unsere Wanderungen konzentrierten sich auf die wunderschönen Rundwege. Zum Beispiel genossen wir eine malerische Rundwanderung vom Markbachjob zum Mittermoosen Speichersee. Auch der Schatzberg bot einen großartigen Rundweg, den wir aus Zeitgründen leider nicht erkunden konnten. In Niederau gibt es im Tal ebenfalls charmante Wege, darunter einen faszinierenden Heilpflanzen Lehrpfad und herrliche Wege entlang der Bergbäche.
Ein Tagesausflug führte uns auch zum Freizeitpark Drachenland in Oberau. Dieser Park kostet keinen pauschalen Eintritt. Jedoch müssen die meisten Attraktionen separat bezahlt werden. Die Achterbahn war zweifellos der Höhepunkt für unsere Kinder. Aus dem Tal bis hoch auf die Alm und dann in engen Kurven wieder hinab. Das Essen war ausgesprochen lecker und zu vernünftigen Preisen erhältlich. Auf eins sei hingewiesen, Schatten auf dem Gelände ist rar. Abgesehen vom Freizeitpark gibt es in der Region Museen, Sporteinrichtungen und ein Freibad, die wir jedoch nicht explizit ausprobiert haben.
Unsere Unterkunft in einem Ferienhaus machte Einkäufe unvermeidlich. Glücklicherweise gibt es in allen Orten der Wildschönau Supermärkte. Dennoch sollte man schauen das das Domizil in Laufentfernung ist, manche Hütte ist auch weiter weg, hier merkt man das die normale Anreise doch mit dem Auto angedacht ist. Unsere Wahl des Ferienresorts erwies sich dabei als klug, da es nicht nur nahe am Markt lag, sondern auch an der Niederauer Seilbahn und der Buslinie.
Der gut organisierte Nahverkehr der Wildschönau trug erheblich zu unserem reibungslosen Aufenthalt bei. Der stündlich verkehrende Bus zwischen Wörgl und Auffach war äußerst praktisch. Zudem gibt es einen Wanderbus rund um Oberau, der weitere Orte anfährt, aber seltener verkehrt. Die Busse waren gut frequentiert, insbesondere ab 10 Uhr, daher empfehle ich, frühzeitig zu reisen, um den Ansturm zu vermeiden.
Lernen mit Bausteinen: Ein Fazit nach vier Jahren
Nach vier Jahren Unischule, möchte ich nun auch noch etwas mehr zum Konzept der Lernbausteine an der Universitätsschule Dresden wieder geben. Dieses pädagogische Konzept zielt darauf ab, das traditionelle lineare Lernen in der Schule aufzubrechen und den Schülern eine individuellere und flexiblere Lernumgebung zu bieten.
Das Ziel der Universitätsschule war es dabei ursprünglich, das Lernen vollständig in Projekten zu gestalten und das Wissen in kleine Bausteine zu zerhacken. Diese Bausteine, die den Lehrplan des sächsischen Lehrplans abdecken, werden in verschiedene “Lernhäuser” unterteilt um eine Grundstruktur zu erhalten. So gibt es beispielsweise ein Lernhaus für sprachliche oder naturwissenschaftliche Bausteine. Die Lernenden haben die Freiheit, die Bausteine in beliebiger Reihenfolge abzuarbeiten. Natürlich gibt es Empfehlungen basierend auf der Klassenstufe oder bestimmte Abhängigkeiten zwischen Bausteinen. Dadurch gab es ein inhaltliche Orientierung für Lernende und PädagogInnen.
Eine der größten Stärken des Konzepts der Lernbausteine liegt im asynchronen Lernen. Lernende haben die Freiheit, je nach Tagesform und individuellem Lernrhythmus ihre Themen zu wählen. Dies ermöglicht es den Lernenden, in ihrem eigenen Tempo zu arbeiten und sich tiefer mit den Themen auseinanderzusetzen, die sie gerade besonders interessieren. Im Vergleich zum starren Stundenplan der herkömmlichen Schule bietet diese Flexibilität den Lernenden die Möglichkeit, ihren Lernprozess besser zu steuern und ihre Motivation aufrechtzuerhalten. Vor allem aber wird eine deutlich bessere Differenzierung möglich und Lernende verlieren nicht so leicht den Anschluss an die Mitlernenden.
Die Einführung des Konzepts der Lernbausteine war jedoch nicht ohne Herausforderungen. Eine der ersten Schwierigkeiten bestand darin, dass keine schulischen Lehrbücher dieses Format unterstützen. Die Lernbegleitenden mussten daher die Inhalte für die einzelnen Bausteine selbst erstellen, was einen erheblichen zeitlichen Aufwand bedeutete. Zudem war die Qualität der Materialien sehr durchwachsen. Im ersten Anlauf waren Bausteine deutlich unterschiedlich in ihrem Umfang, ihrer Gestaltung und dem Schwierigkeitsgrad. Einige Bausteine verloren innerhalb kürzester Zeit ihre Gültigkeit und mussten ein zweites Mal erstellt oder aufgeteilt werden. Dies führte unter anderem dazu, dass sowohl Lernende, Lernbegleitende und Eltern den Überblick verloren was schon erledigt und was zu erledigen war.
Da es nur wenige frontale Unterrichtseinheiten gibt, stützen sich viele Materialien auf digitale Inhalte. Dadurch variiert die Qualität der Erklärungen sehr stark. Ebenfalls stellte sich schnell heraus das Links ins Internet flüchtig sind und schnell ungültig werden können. Auch ist das ausdrucken dynamischer URLs nicht besonders komfortabel, weshalb teilweise dann mit QR Codes in den Materialien hantiert wurde. Dabei schaffte es etwas Linderung die Bausteine auch digital in einem Padlet abzulegen und Links dort oder im PDF Dokument direkt zu verankern und ggf. zu bearbeiten.
Eine weiteres Phänomen, welches wir beobachten konnten, war Druck eine bestimmte Anzahl von Bausteinen pro Woche abzuschließen. Da die Bausteine den Lehrplan abdecken, entstand eine Erwartungshaltung, dass sie in großem Umfang absolviert werden müssten. Dies führte in unserem Fall dazu das Lernbegleitende Druck auf Lernende ausübten, insbesondere wenn das Lerntempo oder die Lernmotivation der Lernenden nicht ausreichten, um die Erwartungen zu erfüllen. Der Tempodruck ersetze dann den Noten- und Leistungsdruck im traditionellen System.
Letztendlich gibt es noch einen Punkt der mir unklar ist. Das Konzept der Bausteine schreit geradezu nach einer trivialen Digitalisierung. Ein Tool in dem alle Bausteine abgelegt sind und in welchem direkt erfasst werden kann mit welchem Erfolg welche Lernenden die einzelnen Bausteine bereits erledigt haben. In vier Jahren Schulportalsoftware wurde das nicht annähernd erreicht, was sich in falschen Zeugnissen und einem unnötigen Wust an Excel Tabellen und Notizen bei den Lernbegleitenden äußerte.
Trotz einiger Herausforderungen und Anpassungen hat sich das Konzept der Lernbausteine an der Universitätsschule Dresden grundlegend als erfolgreich erwiesen. Die Möglichkeit des asynchronen Lernens und die individuelle Auswahl der Bausteine ermöglichen den Lernenden eine flexiblere und eigen motivierte Herangehensweise an das Lernen. Es bleibt jedoch wichtig, den Druck und die Erwartungen im Zusammenhang mit der Absolvierung der Bausteine zu beachten und eine ausgewogene Balance zu finden.
Es sollte darauf geachtet werden, dass die Schüler ihr eigenes Lerntempo und ihre Motivation berücksichtigen können, um den Lernprozess positiv zu gestalten. In meinen Augen eine Aufgabe welche die Lernbegleitenden wahrnehmen müssten, aber nicht können da personelle Engpässe und Fluktuation, große Gruppen mit großer Diversität, fehlende Zusatzqualifikation und Zusatzaufgaben sie daran hindern.
Es wäre toll, wenn sich dieses Konzept weiterentwickelt und auch an anderen Schulen eingesetzt wird, so dass es für Verlage attraktiv wird ihre Lehrmaterialien in einer bausteinartigen Struktur anzubieten. Dies könnte dazu beitragen, den traditionellen Frontalunterricht zu überwinden und eine Lernumgebung zu schaffen, die den Bedürfnissen der Schüler besser gerecht wird.
Insgesamt glaube ich das der Ansatz der Lernbausteine ein innovativer und erfolgreicher Teil des Schulkonzeptes ist, welcher noch großes Potential hat. Vor allem würde man ihn konsequent digital denken und realisieren.
Abschließend möchte ich betonen, dass dies meine persönliche Meinung ist und andere Eltern und Lernende möglicherweise unterschiedliche Ansichten haben.
Agile Methoden: Mehr als nur Reagieren auf Veränderung
In einer sich ständig wandelnden Welt sind Organisationen darauf angewiesen, flexibel und anpassungsfähig zu sein. Agile Methoden haben sich als wirkungsvoller Ansatz erwiesen, um Flexibilität, Innovation und Resilienz zu fördern. Ich möchte heute dem Gedanken nachgehen, ob Agilität oft nur als Reaktion auf Veränderungen betrachtet werden kann.
Agilität wird oft als die Fähigkeit interpretiert, auf Veränderungen zu reagieren. In der Tat sind agile Methoden wie Scrum oder Kanban darauf ausgerichtet, sich flexibel an neue Anforderungen anzupassen. Durch kurze Feedbackschleifen und iterative Entwicklung können Teams schnell auf Veränderungen reagieren und Anpassungen vornehmen. Betrachtet man Agilität jedoch als ausschließlich reaktive Maßnahme führt dies nach meiner Erfahrung schnell zu Frust und Resignation. Das eigentliche volle Potenzial von Agilem Vorgehen bleibt dabei unauszugeschöpft.
Vielmehr setzt eine agile Denkweise proaktives Handeln voraus. Es geht darum, Veränderungen frühzeitig zu erkennen, vorausschauend zu agieren und Innovation voranzutreiben. Agile Methoden bieten eine Vielzahl von Werkzeugen und Praktiken, um kontinuierliches Lernen, Feedback und Anpassungen zu fördern. Gern wird dies dann als empirisches oder evidenzbasiertes Handeln beschreiben. Es ermöglicht es Chancen zu erkennen, Herausforderungen zu bewältigen und Innovationen voranzutreiben, bevor der Zwang entsteht rein reaktiv zu handeln.
Ist das Kind erst einmal in den Brunnen gefallen liegt der ganze Fokus dann auf den Auswirkungen einer Veränderung. Eine andere wichtige Perspektive, die dann häufig übersehen wird, ist der Blick auf die Ursachen und Auslöser. Dem Prinzip der Selbsterhaltung von Systemen folgend ist es wichtig, die zugrunde liegenden Ursachen und Auslöser zu verstehen, um gezielt sich wiederholende Muster zu identifizieren und diese zu unterbrechen. Klarheit zwischen Ursachen und Auswirkungen zu erkennen und zu verstehen, schädliche Muster zu unterbrechen führt langfristig dazu Stabilität zu schaffen, sowie Innovation und Resilienz zu fördern.
Am Ende steht eine ausgewogene Herangehensweise, die sowohl Reaktion als auch Aktion umfasst. Vorausschauendes Handeln und Stabilität schaffen den Raum für schnelle Reaktionen auf unvorhergesehene Veränderungen. Daraus resultiert das Systeme und Organisationen, die frühzeitig agile und evidenzbasierte Methoden einsetzen, um vorausschauend zu handeln, werden besser in der Lage sein, sich an Veränderungen anzupassen und Chancen zu nutzen.
Zusammenfassend möchte ich sagen: Agilität ist mehr als nur eine Reaktion auf Veränderungen - sie ist ein ganzheitlicher Ansatz zum Umgang mit Komplexität. Durch den Fokus auf kontinuierliches Lernen, flexible Anpassung und die Nutzung von Komplexität als Chance für Innovation verbessert sich die Fähigkeit, in einer dynamischen und unvorhersehbaren Welt erfolgreich zu agieren.
